Unlike database tables which are used for long term data storage, the internal tables are temporary tables created and used during the program execution, being deleted prior to the program being terminated. They are used for storing the dynamic data that it sets from a (subset of a) fixed structure in the main/working memory in ABAP.
In effect, internal tables act as arrays (or even better lists – as their size is actually not fixed) in ABAP and are the most complex data objects in ABAP environment. They are most often used for storing and formatting data from a database table within a program.
Internal tables are characterised by the following properties:
- table type determines the access type that specifies how ABAP accesses the individual table rows
- row type determines the column that is declared with any ABAP data type
- uniqueness of the key specifies the key as unique or non-unique
- key components specify the criteria based on which the table rows are identified
They are most often used as snapshots of database tables (of one or even several tables), or as containers for volatile data.
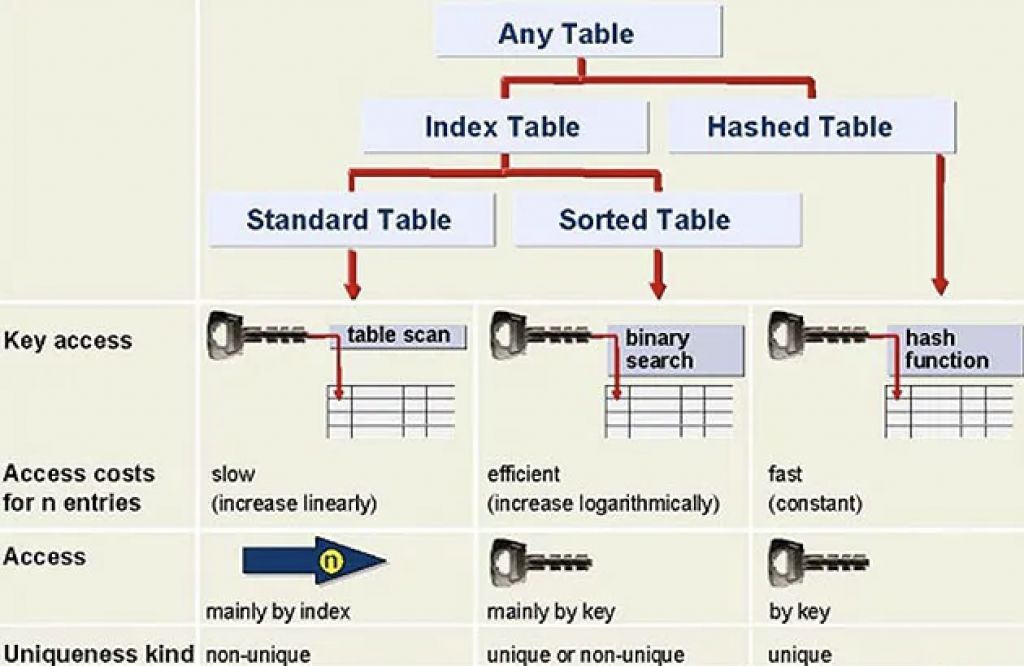
Internal Table Types
There are three types of internal tables in SAP ABAP programming:
- standard internal tables
- sorted internal tables
- hashed internal tables
| Standard Tables | Sorted Tables | Hashed Tables |
| These are default internal tables. | These are a special type of internal tables, where data is automatically sorted when the record is inserted. | These are used with logical databases. |
| It is an index table. | It is an index table. | It is NOT an index table. |
| Table has a non-unique key. | Table has a unique key. | Table key is unique and no duplicate entries are allowed. |
| Access by linear table index or key. | Access by linear index or sort key. | Direct access only by table key. |
| Either key or index operation used to read a record. | Either key or index operation used to read a record. | Key operation used to read the record. Index operation is not allowed. |
| Either linear search or binary search used to search for a record. | Binary search used to search for a record. | Hashed algorithm used to search for a record. |
| Data is not sorted by default and can use sort operation to sort the data. | Data already sorted. | Data already sorted. |
| Records can be inserted or appended. | Records can be inserted. | Used in ABAP with BI projects. |
| Response time proportional to table size. | Response time logarithmically proportional to table size. | Constant, fast response time. |
Usage
Standard tables are most appropriate for general table operations. Accessed by referring to the table index (which is the quickest access method). Access time for standard table increases linearly with respect to the number of table entries. New rows are appended to the table. Individual rows are accessed by reading the table at a specified index value.
Sorted tables are most appropriate where the table is to be filled in sorted order. Sorted tables are filled using the INSERT statement. Inserted entries are sorted according to a sort sequence defined by the table key. Illegal entries are recognized as soon as you try to insert them into the table. Response time is logarithmically proportional to the number of table entries (since the system always uses a binary search). Sorted tables are particularly useful if you wish to process row by row using a LOOP.
Hashed tables are most appropriate when access to rows is performed by a key. Cannot access hashed tables via the table index. response time remains constant regardless of the number of rows in the table.